Additional training functions¶
These methods are automatically added to all Learner objects created after importing this module. They provide convenient access to a number of callbacks, without requiring them to be manually created.
See OneCycleScheduler for details.
See LRFinder for details.
See MixedPrecision for details.
See MixUpCallback for more details.
For example in ClassificationInterpretation is implemented using argmax on preds to set self.pred_class whereas an optional sigmoid is used for MultilabelClassificationInterpretation
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
learn = cnn_learner(data, models.resnet18)
learn.fit(1)
preds,y,losses = learn.get_preds(with_loss=True)
interp = ClassificationInterpretation(learn, preds, y, losses)
Returns tuple of (losses,indices).
If normalize, plots the percentages with norm_dec digits. slice_size can be used to avoid out of memory error if your set is too big. kwargs are passed to plt.figure.
interp.plot_confusion_matrix()

interp.confusion_matrix()
Working with large datasets¶
When working with large datasets, memory problems can arise when computing the confusion matrix. For example, an error can look like this:
RuntimeError: $ Torch: not enough memory: you tried to allocate 64GB. Buy new RAM!
In this case it is possible to force ClassificationInterpretation to compute the confusion matrix for data slices and then aggregate the result by specifying slice_size parameter.
interp.confusion_matrix(slice_size=10)
interp.plot_confusion_matrix(slice_size=10)
interp.most_confused(slice_size=10)
Additional callbacks¶
We'll show examples below using our MNIST sample. As usual the on_something methods are directly called by the fastai library, no need to call them yourself.
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
learn = cnn_learner(data, models.resnet18, metrics=accuracy, callback_fns=ShowGraph)
learn.fit(3)
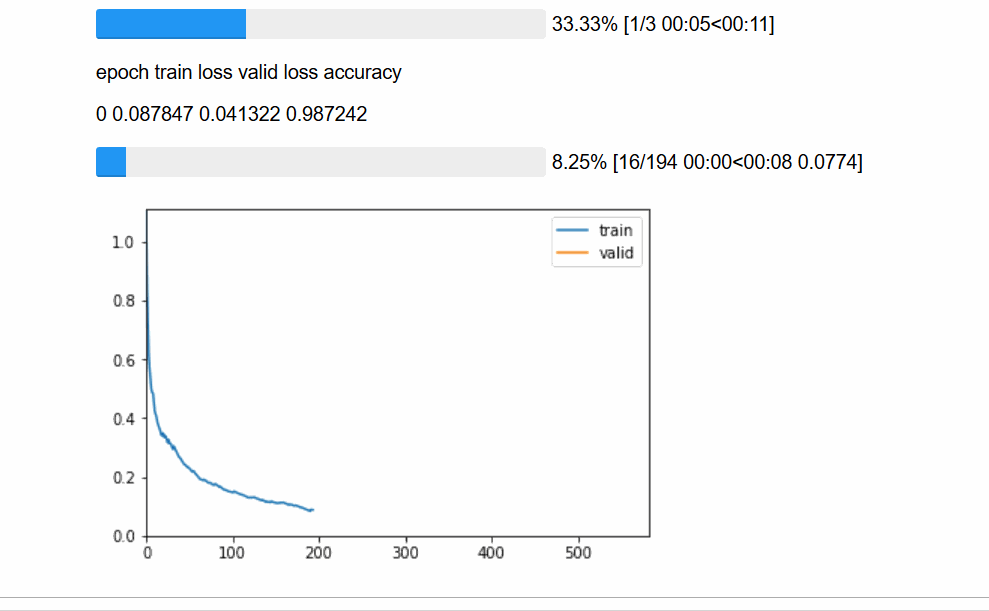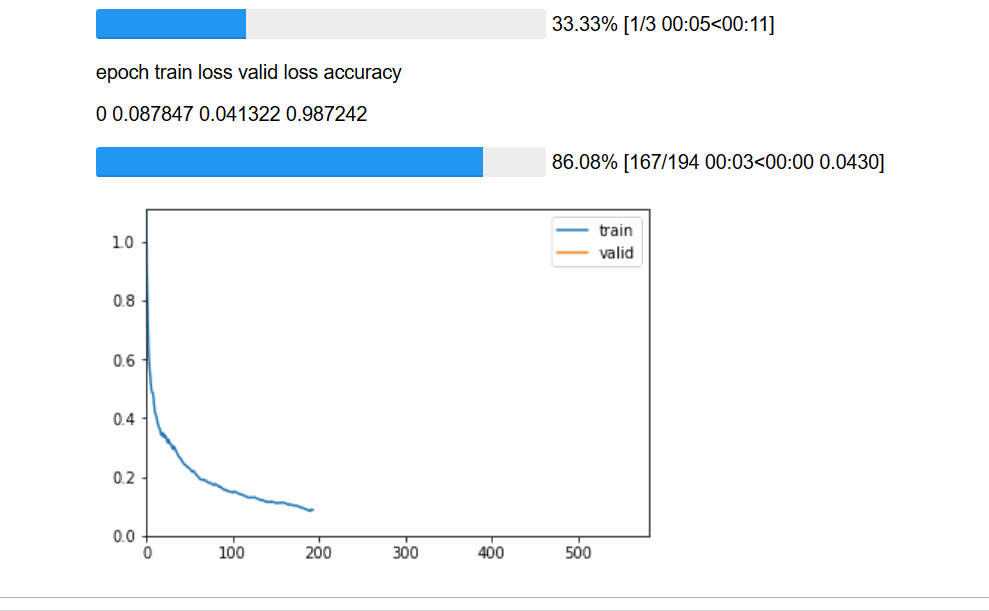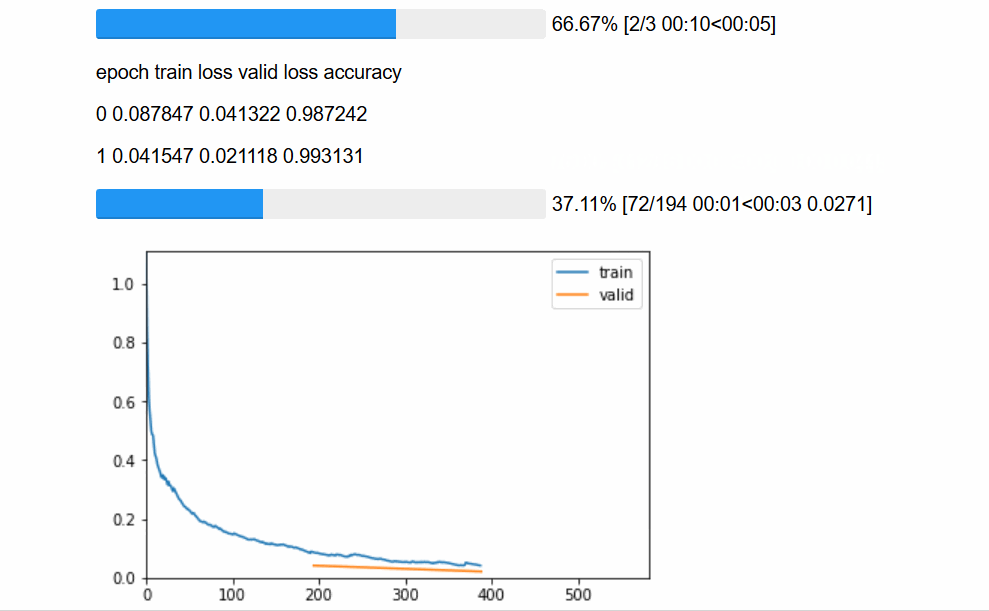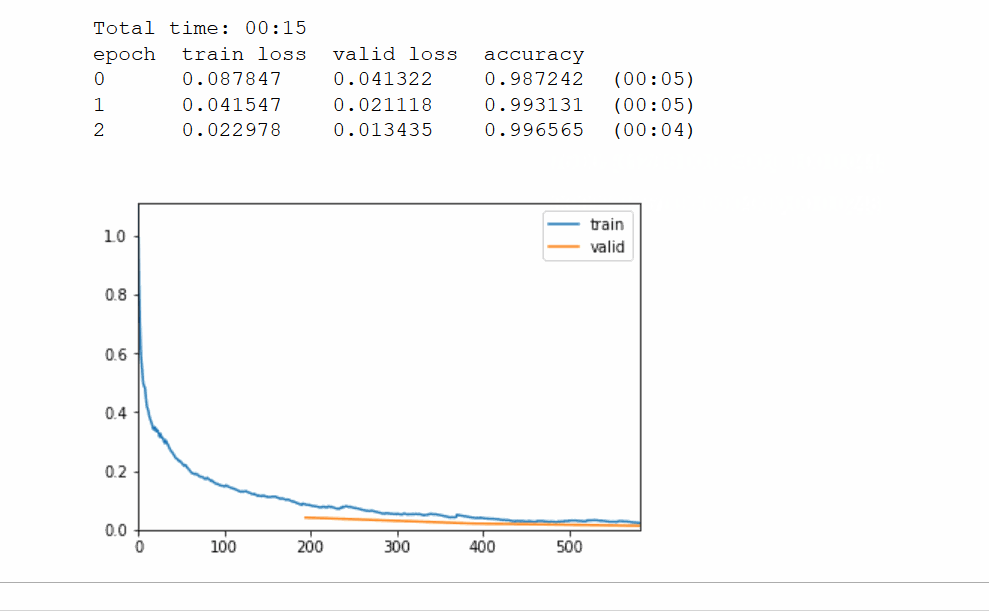
learn = cnn_learner(data, models.resnet18, metrics=accuracy,
callback_fns=partial(GradientClipping, clip=0.1))
learn.fit(1)
For batchnorm layers where requires_grad==False, you generally don't want to update their moving average statistics, in order to avoid the model's statistics getting out of sync with its pre-trained weights. You can add this callback to automate this freezing of statistics (internally, it calls eval on these layers).
learn = cnn_learner(data, models.resnet18, metrics=accuracy, callback_fns=BnFreeze)
learn.fit(1)
Let's force batch_size=2 to mimic a scenario where we can't fit enough batch samples to our memory. We can then set n_step as desired to have an effective batch_size of effective_batch_size=batch_size*n_step.
It is also important to use loss func with reduce='sum' in order to calculate exact average accumulated gradients.
Another important note for users is that batchnorm is not yet adapted to accumulated gradients. So you should use this callback at your own risk until a hero fixes it :)
Here we demonstrate this callback with a model without batchnorm layers, alternatively you can use nn.InstanceNorm or nn.GroupNorm.
from torchvision.models import vgg11
data = ImageDataBunch.from_folder(path, bs=2)
learn = cnn_learner(data, resnet18, metrics=accuracy, loss_func=CrossEntropyFlat(reduction='sum'),
callback_fns=partial(AccumulateScheduler, n_step=16))
learn.fit(1)