Dynamic U-Net¶
This module builds a dynamic U-Net from any backbone pretrained on ImageNet, automatically inferring the intermediate sizes.
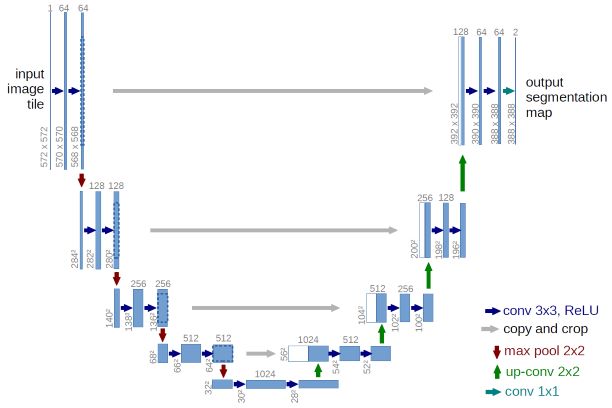
This is the original U-Net. The difference here is that the left part is a pretrained model.
This U-Net will sit on top of an encoder (that can be a pretrained model) and with a final output of n_classes. During the initialization, it uses Hooks to determine the intermediate features sizes by passing a dummy input through the model and create the upward path automatically.
blur is used to avoid checkerboard artifacts at each layer, blur_final is specific to the last layer. self_attention determines if we use a self attention layer at the third block before the end. If y_range is passed, the last activations go through a sigmoid rescaled to that range. last_cross determines if we use a cross-connection with the direct input of the model, and in this case bottle flags if we use a bottleneck or not for that skip connection.
This block receives the output of the last block to be upsampled (size up_in_c) and the activations features from an intermediate layer of the encoder (size x_in_c, this is the lateral connection). The hook is set to this intermediate layer to store the output needed for this block. final_div determines if we divide the number of features by 2 with the upsampling, blur is to avoid checkerboard artifacts. If leaky is set, use a leaky ReLU with a slope equals to that parameter instead of a ReLU, and self_attention determines if we use a self-attention layer. kwargs are passed to conv_layer.